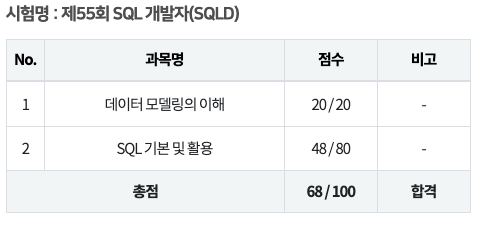
※ 이 포스팅은 쿠팡 파트너스 활동 일환으로, 이에 따른 일종의 수수료를 제공받습니다. 2024년 11월에 어쩌다보니 SQLD 시험을 보게되었다. 하필 회사에서의 일도 바빴기때문에 공부할 시간이 많이 부족했다. 그래서 일단 합격을 목표로 공부를 하기 시작했고, 시간을 효율적으로 쓰기위해 선택과 집중을 하였다. 일단 과목별로 우선순위를 정하여 공부를 하였고 우선순위가 낮은 과목은 과감히 공부를 하지 않았다. 특히, 비전공자이면서 학점은행제로 인해 SQLD 합격이 필요한 사람들은 나의 방법을 적용하면 좋은 결과를 받을 수 있을 것이다. 다음은 SQLD를 12시간 공부하면서 적용했던 방법이다. 1. 1과목 "데이터 모델링의 이해"는 무조건 다 맞는다는 생각으로 외운다.1과목을 다 맞으면 총 20점이다. 내용..